Abstract
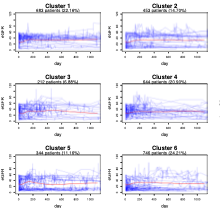
Longitudinal disease subtyping is an important problem within the broader scope of computational phenotyping. In this article, we discuss several data-driven unsupervised disease subtyping methods to obtain disease subtypes from longitudinal clinical data. The methods are analyzed in the context of chronic kidney disease, one of the leading health problems, both in the USA and worldwide. To provide a quantitative comparison of the different methods, we propose a novel evaluation metric that measures the cluster tightness and degree of separation between the various clusters produced by each method. Comparative results for two significantly large clinical datasets are provided, along with key insights that are possible due to the proposed evaluation metric.
BibTex
@article{Luong2019,
author="Luong, Duc Thanh Anh and Singh, Prerna and Ramezani, Mahin and Chandola, Varun",
year="2019",
journal="Journal of Healthcare Informatics Research",
year="2019",
volume="3",
number="4",
pages="441--459",
}